Tanggungjawab Pentadbir Hadoop
Blog mengenai tanggungjawab Hadoop Admin ini membincangkan skop pentadbiran Hadoop. Pekerjaan pentadbir Hadoop mendapat permintaan tinggi jadi pelajari Hadoop sekarang!

Blog mengenai tanggungjawab Hadoop Admin ini membincangkan skop pentadbiran Hadoop. Pekerjaan pentadbir Hadoop mendapat permintaan tinggi jadi pelajari Hadoop sekarang!
Apache Spark telah muncul sebagai perkembangan besar dalam pemprosesan data besar.
Apache Hadoop 2.x terdiri daripada peningkatan ketara berbanding Hadoop 1.x. Blog ini membincangkan mengenai Hadoop 2.0 Cluster Architecture Federation dan komponennya.
Ini memberi gambaran mengenai penggunaan Job tracker
Babi Apache mempunyai pelbagai fungsi yang telah ditentukan. Catatan itu mengandungi langkah-langkah yang jelas untuk membuat UDF di Babi Apache. Di sini kodnya ditulis di Java dan memerlukan Pig Library
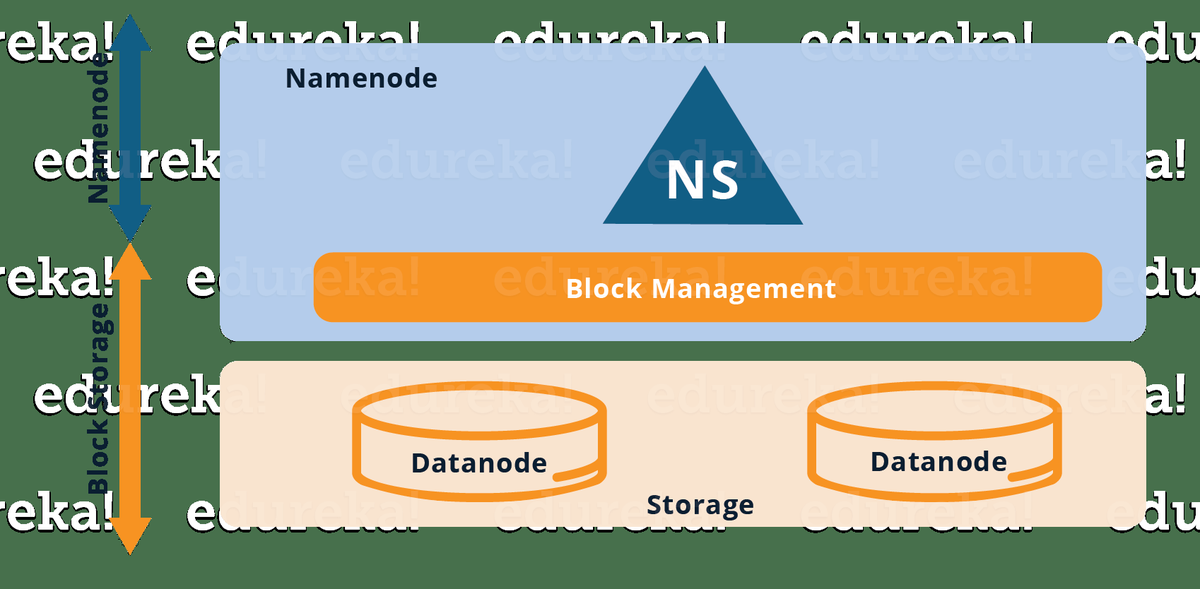
Di sana, senibina HBase Storage merangkumi banyak komponen. Mari lihat fungsi komponen-komponen ini dan ketahui bagaimana data ditulis.
Apache Hive adalah pakej Pergudangan Data yang dibina di atas Hadoop dan digunakan untuk analisis data. Hive disasarkan kepada pengguna yang selesa dengan SQL.
Pelaksanaan Apache Spark dengan Hadoop secara besar-besaran oleh syarikat terkemuka menunjukkan kejayaan dan potensinya ketika datang ke pemprosesan waktu nyata.
Ketersediaan Tinggi NameNode adalah salah satu ciri terpenting Hadoop 2.0 Ketersediaan Tinggi NameNode dengan Pengurus Jurnal Kuorum digunakan untuk berkongsi log edit antara Node Nama Aktif dan Siap.
Tanggungjawab pekerjaan pembangun Hadoop merangkumi banyak tugas. Tanggungjawab pekerjaan bergantung pada domain / sektor anda. Peranan ini serupa dengan Pembangun Perisian
Model data Hive mengandungi komponen berikut seperti Pangkalan Data, Jadual, Partition dan Bucket atau kluster. Sarang menyokong jenis primitif seperti Integers, Floats, Doubles and Strings.
4 alasan ini untuk meningkatkan ke Hadoop 2.0 membincangkan mengenai pasaran pekerjaan Hadoop dan bagaimana ia dapat membantu anda mempercepat kerjaya dengan membuat anda terbuka untuk peluang pekerjaan yang besar.
Di blog ini, kita akan menjalankan contoh Hive and Yarn di Spark. Pertama, bina Hive dan Benang di Spark dan kemudian anda boleh menjalankan contoh Hive dan Benang di Spark.
Objektif blog ini adalah untuk mempelajari cara memindahkan data dari pangkalan data SQL ke HDFS, cara memindahkan data dari pangkalan data SQL ke pangkalan data NoSQL.
Pembangun Bersertifikat Cloudera untuk Apache Hadoop (CCDH) adalah peningkatan kerjaya seseorang. Catatan ini membincangkan faedah, corak peperiksaan, panduan belajar dan rujukan berguna.
Blog ini memberikan gambaran umum mengenai seni bina Ketersediaan Tinggi HDFS dan cara mengatur dan mengkonfigurasi kluster Ketersediaan Tinggi HDFS dengan langkah mudah.
Apache Kafka terus popular ketika datang ke Analisis Masa Nyata. Berikut adalah pandangan dari sudut kerjaya, membincangkan peluang kerjaya dan tuntutan pekerjaan.
Apache Kafka menyediakan sistem pemesejan throughput tinggi & berskala yang menjadikannya popular dalam analisis masa nyata. Ketahui bagaimana tutorial kafka Apache dapat membantu anda
Catatan blog ini adalah mendalam mengenai Babi dan fungsinya. Anda akan menemui demo bagaimana anda boleh mengusahakan Hadoop menggunakan Babi tanpa bergantung pada Java.
Blog ini membincangkan prasyarat untuk belajar Hadoop, Java penting untuk Hadoop & jawapan 'adakah anda memerlukan Java untuk belajar Hadoop' jika anda tahu Babi, Hive, HDFS.